
Tag: coding
-

Debunking Japanese dual-nationality myths with code
Every single post on Japan-related subreddits that mentions someone is binational will have a bunch of commenters jump in to say it’s illegal, OP needs to hide it or they will be made to renounce as soon as they turn 20. While this is true for people who naturalized to a foreign nationality, it’s patently…
-
Zip R2 Objects in Memory with Cloudflare Workers
How to serve a list of files stored in R2 as a Zip file through Cloudflare Workers all in memory.
-
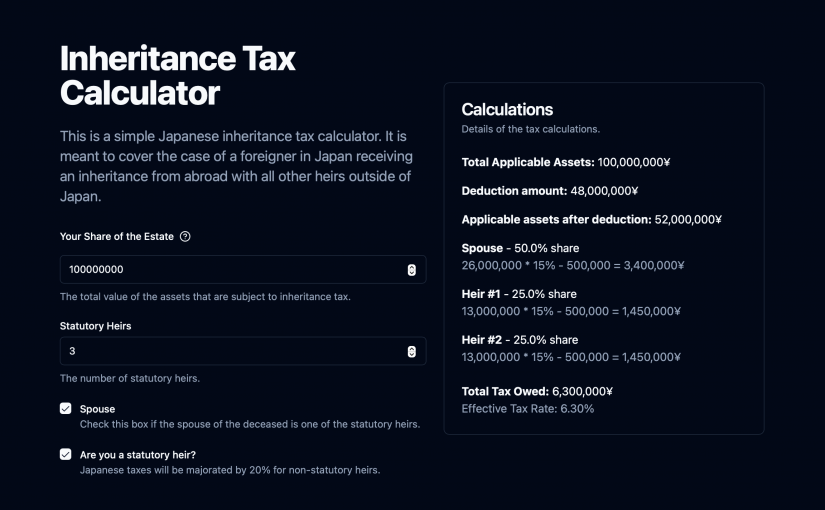
Simple Japanese Inheritance Calculator
I made a thing again! If you’re like me, a foreigner in your 40s living in Japan, the thought of dealing with inheritance taxes for your parents back home can be daunting. Understanding how these taxes might be applied is essential. To help with this, I created an app: Japanese Inheritance Tax Calculator. Here are…
-
New Feature: Deep Linking
Yesterday I did a bit of coding and added a new feature to Sunsetter: deep linking. When you make a query to find a sunrise or sunset forecast, the address bar will update with a link you can copy and share or send to friends to show the same page you were on. For example,…
-

Predicting Manhattanhenge
There has been a lot of talk lately about the Manhattanhenge, the 2 days in the year when the sun sets in the alignment of New York streets (thank you city grid design). It’s awesome to see so many pictures like this popping up on flickr and instagram because this way I also get to…
-
Sunsetter – Open Sourced
I’ve open sourced my little Sunsetter project on Github. You can see my ugly ugly code there, though I’ll try to make it a little more professional as we go.
-

Pet Project: Sunsetter
At home I have a nice view of the Fujisan to the south-west. I often take pictures of it in winter when the skies are so clear. Many times I’ve told myself it would be nice to take a picture with the sun setting right behind the mountain. I’ve searched the internet for an app…
-
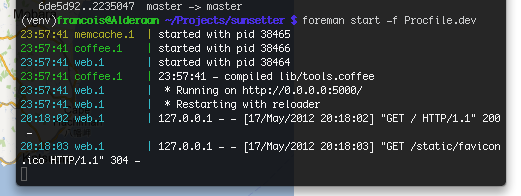
Foreman and Procfile tips&tricks
Lately I’ve been playing around with the Heroku stack and I’d like to share little tricks that might be common knowledge but which I’ve not seen mentioned on the Heroku standard documentation. So the doc tells you you must set your Procfile as such (for a Python app): web: gunicorn app:app -b 0.0.0.0:$PORT -w 3 You can…
-
WWDC Keynote on MacBidouille.com with App Engine
No bandwidth, no servers, no infrastructure, no money required. Just a bit of python and a tad of javascript and you can live stream an event to 10.000 people concurrently (theoretic figure, Analytics said the live-blog site had 30.000 visits in all) within Google App Engine‘s free quotas. This is the graph taken from my…
-
Blacklisting words in Twitter Tools
There’s a new game trending on Twitter these days, Spymaster, and it likes to write out stuff to your twitter feed. There’s a good controversy running on the web whether these tweets are spam or not. I’m playing and I’ve set it up to tweet out only level ups which is pretty minimalist. However, I…
-
Meta-tags proposal for the new DiggBar
Many think the DiggBar is evil. I don’t. I find it ingenious, especially the digg.com pre-pending which will automatically generate a shortened URL for you as well as a “Submit to Digg” button if the page URL has not been submitted yet. However, when you submit a link to Digg by this way, the title…
-
Twitter integration
As you might have noticed, in the past weeks I have more tightly integrated my twitter messages into the blog. When they used to just show up in the sidebar, they are now posted simultaneously here as full blog posts, albeit with a special minimalistic styling. You can clickity-click on the cute blue birdie to…
-
WWDC Keynote
Tonight (at least in Japanese time) is Steve Job’s WWDC Keynote. It is widely accepted that he will be announcing the new 3G enabled iPhone and I am secretly hoping he will give us a release date for Japan live from the Moscone West. These past weeks, I’ve been developing a live-blogging system for my…
-
Playing with Twitter
I’ve started using Twitter today and implemented it on my blog’s sidebar with the cool Twitter Tools plugin. You can see my latest entries to the right, under the search on the main page of the blog. I’ll use that to post all the one-liner updates that I never bother to post here for fear…